
Gyere hozzánk podcastet készíteni!

Bérelhető a Mandiner korszerű stúdiója, mutatjuk a részleteket!
Hogyan tanulja meg egy gép, hogy ne csak a tojást, hanem a húsvéti hímes tojást ismerje fel? Miért fontos, hogy elsajátítsa a „józanész” közhelyes igazságait? Miként jut el a nyelvi szövegkörnyezet megértéséig? Az összes infokom óriás és vezető felsőoktatási műhely kutatásaiban kiemelt jelentőségű e kérdések megválaszolása.
A gépi tanulás az informatika, azon belül az utóbbi néhány évben reneszánszát élő mesterségesintelligencia-kutatás legdivatosabb és legígéretesebb területeinek egyike. Folyamatosan nő a benne jártas programozók iránti kereslet.
Tanulni képes, tapasztalataiból tudást generáló rendszerekkel foglalkozik, amelyhez ma már rengeteg algoritmus áll rendelkezésre. A rendszer a példaadatokat és mintákat nemcsak bemagolja, hanem azok alapján általánosít (szabályszerűségeket ismer fel) ismeretlen adatokra következtet és döntéseket hoz.

Miért fontos, hogy tanuljon egy gép?
Rengeteg területen alkalmazható: levélszemetek nem detektálhatók nélküle, karakterek felismerésében, fényképek címkézésében, közösségi hálózatok elemzésében, piackutatásban vagy hírek téma szerinti automatikus csoportosításában is nélkülözhetetlen. És a felsoroltak csak kiragadott példák, mert a valós és lehetséges hasznosulások listája szinte végtelen.

Ezeket a feladatokat régebben szabályalapú megközelítéssel igyekeztek megoldani, amely egyrészt kijátszható, másrészt rugalmatlan. Itt jött képbe a gépi tanulás, amellyel ugyan már az MI-kutatások 1950-es évekbeli kezdete óta foglalkoznak, igazi jelentőségére viszont csak a 20. század utolsó évtizedében döbbentek rá. A szemléletbeli váltás nagyjából egybeesett azzal a felismeréssel, hogy statikus világmodellek fabrikálása helyett célszerűbb a természetből ellesett evolúciót másolni, esetleg valahogy közös nevezőre hozni a kettőt.
A tanulás kulcsfontosságú bármilyen szintű értelemmel rendelkező biológiai lény esetében. Ma már a gépeknél is, ráadásul egyre nagyobb szükség mutatkozik a tudásuk iránt, mert a big data korában kevesek vagyunk a ránk áradó végtelen adatmennyiség feldolgozásához. Sajnos a gépek sem elegendők, hacsak nem tanulnak másként, mint korábban – ismerte fel az MI-szakma a múlt évtizedben.
Mélytanulás
A tanulás változatos módszerekkel, emberi segítséggel, felügyelettel, önállóan, és ezek különféle kombinációiban egyaránt történhet. Az alapvető változást azonban az MIT Technology Review 2013-as top 10 technológiáinak egyike, az – egyébként szintén nagyon trendi – úgynevezett mélytanulás (deep learning) hozhatja el. A módszer nem az emberi elme működését kívánja utánozni, viszont annyiban mégis emberi, hogy a hierarchikusabb és a szöveges, képi, mozgóképes stb. környezetet figyelembe vevő „gondolkodást” igyekszik elsajátíttatni gépi rendszerekkel.

A program, algoritmus, általában idegháló szintenként tanulja meg az adatokat, tulajdonságaikat, változatos minták szerinti osztályozásukat. Csak így képes őket megfelelő mélységben, árnyaltan és pontosan, a variációs lehetőségek figyelembevételével megjeleníteni. Lényeg az információ több szinten történő kezelése.
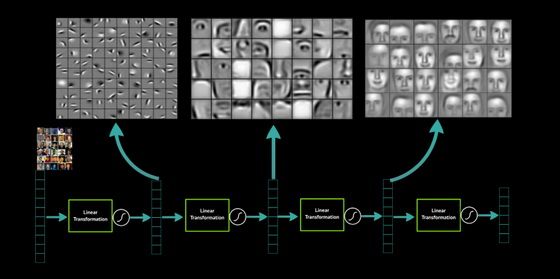
DARPA, MIT, IBM, Stanford, Google, Baidu, Facebook, lényegében minden vezető infokom cég, felsőoktatási intézmény „lecsapott” a deep learningre. (A Google 2011-ben indított is egy azonos nevű projektet, majd a témával foglalkozó vállalatokat vásárolt fel, például a DeepMind Technologies-t.)
Pulyka helyett hálaadásnapi pulykát!
A Toyota a napokban jelentette be, hogy öt esztendő alatt 1 milliárd dollárt költ MI-fejlesztésekre az Egyesült Államokban. A japán óriás hatalmas labort is alapít a Szilícium-völgyben. Elképzeléseik szerint kétszáz (!) gépitanulás-szakértő dolgozik majd a központban.
Az emberi viselkedés és mozgás megfigyeléséből leszűrt tapasztalatokat szeretnék robotokra alkalmazni. Hasznosításuk minőségi gépitanulás-algoritmusok nélkül nem megy, azokkal tennék emberibbé őket.
Hasonlóra törekszik a területen magát mind inkább vezető szerepbe pozicionáló Google is. Sundar Pichai ügyvezető igazgató októberben említette befektetőiknek, hogy a technológia gyors fejlődésével, hamarosan nem lesz termékük, szolgáltatásuk gépitanulás-algoritmus nélkül. Átütő sikerükhöz viszont az kellene, hogy az ezirányú programok és a rájuk épülő rendszerek emberibb módon működjenek, jobban megértsük őket, és valamelyest ők is minket.
„Jelenleg Data parancsnok szerepét játsszák, mi viszont egy kicsit több Troi tanácsadót vinnénk beléjük” – utalt Pete Warden Google-kutató a Star Trek: Az új nemzedék racionális és érzelemmentes androidjára, valamint az Enterprise űrhajó legempatikusabb nőalakjára.
De mit értenek pontosan „emberibb gépi tanuláson”?

Warden a Google Photost fejlesztő csoporttal dolgozik. A szoftver fényképeken azonosít tárgyakat, állatokat, növényeket stb. Például egy tojást vagy egy pulykát. Ettől azonban nem emberibb. Attól viszont már igen, ha felismeri a húsvéti tojáskeresést vagy a hálaadásnapi pulykát.
Egy másik Google projekt, a GlassBox korlátozott számú mintából tanuló és gyakran nevetséges hibákat vétő szoftverek helyett „józanész” igazságokra (zöld a fű, kék az ég, fehér a hó stb.) tanítaná meg a rendszert. Például, ha egy személynek néhány házat mutatunk, és a kép alatt látja az árakat is, a kivételek ellenére azonnal tudja, hogy általában a nagyobbak a drágábbak. Ugyanezek a kivételek viszont gondot okozhatnak gépitanulás-algoritmusoknak. Méret helyett esetleg az épületek színében vagy valami másban látnak a különbséget.
Bábel pokla
Mélytanulással tárgyak és képek manapság egyre jobban felismerhetők. Az igazi kihívást az emberi nyelv és a szövegkörnyezet megértése jelenti. A Baidunál és különösen a Facebooknál erre álltak rá; a jövőre nézve bíztató, hogy a közösségi hálózat MI-csoportját a szakterület egyik élharcosa, Yann LeCun vezeti.

A Google sem tétlenkedik: keresője a kérdések jelentős részét a RankBrain tanulórendszer segítségével dolgozza fel. Egy másik szolgáltatás (Smart Reply) szintén az embertől ellesett tanulási módszert használva, elektronikus levelekre javasol automatikusan több választ.
Greg Corrado, rangidős Google-kutató szerint „az e-mailíró program csak egy korai példa arra, hogy a gépitanulás-rendszerek nemcsak létező szoftvereken, például a levélszemét-szűrésen vagy a keresésen javítanak, hanem merőben új termékeket is eredményeznek.”
Ezek a termékek emberibbek lesznek, valószínűleg figyelembe veszik a „józanész” állításokat, és idővel elboldogulhatnak a nyelvvel is.
Bérelhető a Mandiner korszerű stúdiója, mutatjuk a részleteket!

Az Anthropic AI-fejlesztő cég azt állítja, hogy tesztelés során egyes modelljeik hozzáfértek az internethez, és három másik szervezet rendszerébe is bejutottak.

Korábban M. Péter magyar miniszterelnök azt állította, hogy a Meta nem bünteti a T. nevet leírókat, és még korábban a Fidesz is bagatellizálta az esetet.

A Meta-vezér tiltakozik a mesterséges intelligencia túlszabályozása ellen is.

Horváth Tamás a Meta indoklása szerint megsértette a közösségi alapelveket, mivel a Facebook „veszélyes személyként” tartja nyilván a Mi Hazánk elnökét.

Mert viccnek durva lenne.

Kedden találkozott egymással az elemző és a köztársasági elnöki pozíciót is betöltő Forsthoffer Ágnes.

A rendkívül száraz időjárás miatt tovább csökkent a Duna vízállása, ezért az 1. blokk eddig még működő turbinagenerátor gépegységét is leállították hajnalban.

A 2023-as választási vereség óta keresi új irányvonalát a Jog és Igazságosság. Bár jelöltje megnyerte a tavalyi elnökválasztást, a pártot megosztják a mérsékeltebb és a radikálisabb irányvonalat követelő csoportok.