
Gyere hozzánk podcastet készíteni!

Bérelhető a Mandiner korszerű stúdiója, mutatjuk a részleteket!
Szerdán a legbonyolultabb táblás játékban, a goban nyert egy mesterségesintelligencia-program a világ legjobbjának tartott versenyző ellen. Hogyan jutott el idáig, most akkor sírjunk vagy nevessünk?
Három dátum
1979. július 15-én Monte Carlóban a Carnegie Mellon Egyetem (CMU) BKG 9.8 programja legyőzte Luigi Villa-t, a backgammon újdonsült világbajnokát. Ez volt az első alkalom, amikor valamilyen elismert szellemi tevékenység number one-ja vereséget szenvedett egy ember által fejlesztett entitástól – programtól, mesterségesintelligencia-programtól…

1996. február 10-én Deep Blue, az IBM sakkozó számítógépe legyőzte az akkori világbajnok Gary Kaszparovot. Deep Blue-nak szintén volt köze a CMU-hoz – 1985-ben ott kezdték el fejleszteni. 1997. májusban ismét asztalhoz ült Kaszparovval, és hat játszmában 3,5-2,5-re verte.
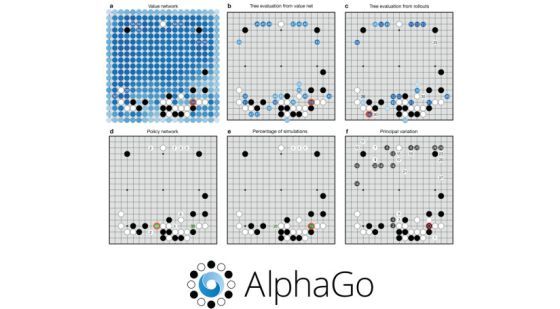
2016. március 9-én a Google AlphaGo go-algoritmus a szöuli Négy Évszak hotelben hatalmas csata után megnyerte a világranglista ötödik helyezett, de a jelenlegi legjobb játékosnak tartott dél-koreai Lee Szedol elleni ötjászmás sorozat első játszmáját. Az agresszív játékstílusáról ismert Szedol 3 óra és 30 perc után feladta. Az AlphaGo tavaly októberben az Európa-bajnok, a világranglistán viszont csak 633. helyen álló kínai származású Fan Huit győzte le 10 játszmából 8 alkalommal.
Backgammon, sakk, go – mesterségesintelligencia-programok mind bonyolultabb logikai játékokban diadalmaskodnak a terület legjobb versenyzői felett. Egyszerűbbtől nehezebbig, a legnehezebbig haladva, közel két évtizedes ciklusokban ugornak szintet.
Mi a go?
A kicsit a sakkra emlékeztető (szintén megnyitásra, közép- és végjátékra bontható) go kínai eredetű, körülbelül 4 ezer – de minimum 2500 – éves táblás játék. Ketten játsszák, viszonylag egyszerű szabályrendszere ellenére rendkívül gazdag a stratégiai lehetőségekben.

A két játékos felváltva helyezi a táblára fekete és fehér köveit egy 19×19 mezős táblán, céljuk, hogy nagyobb területet foglaljanak el ellenfelüknél. A táblára tett kövek csak akkor mozdíthatók el, ha elfogták őket. Az elfoglalt területeket és elfogott köveket a játék végén számolják össze, abból derül ki, hogy ki szerzett több pontot. Pontozás mellett úgy is nyerhetünk, ha az ellenfél feladja.

Régészeti leletek tanúsága alapján a legősibb változatot 17x17-es táblán játszották Kínában. Koreába az 5., Japánba a 7. században már 19x19-ben jutott el. A nyugati világban a 19. század vége óta népszerű. A legtöbb versenyen mérik a játékosok idejét, mindketten egyenlő eséllyel indulnak, bár ritkán, de lehet hendikeppel is.
Go és mesterséges intelligencia
A go annyira összetett, hogy sokáig bármelyik jobb versenyző megverte a legjobb programot. Pont a komplexitása miatt egyre divatosabb az MI-kutatásban. Mivel a sakknál exponenciálisan összetettebb, világbajnokok megveréséhez a sakkprogramokénál jóval kifinomultabb algoritmikus elvek kellenek.
Az első áttörésre az Amerikai Gokongresszus 2008 augusztusában rendezett versenyén került sor, amikor a francia MoGo, igaz 9 kő előnnyel indulva, de legyőzte Myungwan Kim dél-koreai nagymestert. A program újabb változata 2009-ben már egyenlő feltételek mellett nyert egy másik nagymester ellen.
Az igazi beindulást azonban a Google és a Facebook színrelépése jelentette. Előttük általában az úgynevezett Monte Carlo keresési/optimalizálási módszerrel próbálkoztak, de tartós sikereket nem értek el vele.
A két mamutcég új megközelítést dolgozott ki, előre meghatározott lépéssorok helyett a képfelismerésre és kategorizálásra, fordításra, hangutasítások feldolgozására használt gépi tanulásból indultak ki. A vizuális és egyben ösztönös, intuitív megközelítés sikere a gépi tanulás legígéretesebb területén, az úgynevezett mélytanulásban (deep learning) előszeretettel használt mintafelismeréstől függ. A Facebook decemberben pontosított: a mélytanulást a Monte Carlo módszerrel kombinálta.

A Google londoni MI laborjában, a DeepMindban két év alatt fejlesztett AlphaGo sikereivel azonban eldőlni látszik a versenyfutás.
A diadalmas AlphaGo
A fejlesztők még tavaly nyáron is azt mondták, hogy tíz év kell egy topjátékos legyőzéséhez. Hatalmasat tévedtek. AlphaGo nemcsak felveszi a versenyt a legjobbakkal, hanem óriási adatmennyiséget elemezve és gyakorolva rajta, saját magától is tanul, és nem akárhogy: októberben még az esélytelenek nyugalmával állhatott volna ki Lee Szedol ellen, március elején viszont már ő nyert. Azóta folyamatosan pallérozta tudományát, egyik játszmát a másik után zavarta le, önmaga volt az ellenfél is.

A gépi tanulás két egymást kiegészítő, kisegítő formáját használja. Elsajátította azt is, hogy hogyan használhatja ki legjobban a rendelkezésére álló időt. Más programokhoz hasonlóan a számításokban rejlik a legfőbb ereje, így képes bővíteni a lehetséges előnyös lépések számát, miközben speciális keresési eljárással következtet a kimenetükre.
Szerdai sikere fejlesztőit is ledöbbentette.
Mit jelent a győzelem?
A világsajtó a mesterségesintelligencia-fejlesztések újabb mérföldkövéről, messzire vezető következményekről beszél, valószínűleg felerősödnek a szigorúbb szabályozást követelő (általában dilettáns) hangok is. Ahogy Deep Blue Kaszparov feletti diadalával sem született világmegváltó vagy rontó MI, ugyanúgy AlphaGo sem teljesíti be tetszés szerint a délibábos álmokat vagy az indokolatlan félelmeket, riogatásokat.

Ne felejtsük el, hogy a go elképesztő komplexitása ellenére is szabályokba zárható, és ugyan az intuíció fontos szerephez jut benne, de a gép győzelméhez nem kellenek azok a tulajdonságok, amelyek megkülönböztetik az értelmet a szimpla intelligenciától: én- és öntudat, intenciók, érzelmek.
A következmények valószínűleg a gépi tanulás még jobb „PR-jában”, a szakterületre csordogáló nagyobb pénzösszegekben és a hétköznapokban is hasznosuló alkalmazásokban lesznek majd mérhetők.
Bérelhető a Mandiner korszerű stúdiója, mutatjuk a részleteket!

Az amerikai törvényhozók meg akarják adni a kormánynak a jogot, hogy gyorsan elrendelhesse a lakosságot fenyegetni látszó mesterséges intelligencia eszközök kikapcsolását.

Döntött az Európai Bizottság.

Éjszakára lekapcsolnák számukra a közösségi felületeket.

Ezt támasztja alá a Samsung negyedéves jelentése is: a vállalat üzemi eredménye a memóriachipek iránti növekvő keresletnek köszönhetően rekordmértékben emelkedett.

Gyurcsány volt embere kilép a pártból is.

Aki most tapsol az erőszakhoz, holnap könnyen kerülhet olyan helyzetbe, hogy ő az áldozat.

A kamuzsoltibacsi.hu címen elérhető oldalon egy nagy „Coming soon”, azaz „Hamarosan érkezik” felirat.

„Történelmi értelemben minden a helyére kerül” – véli az orosz elnök.