Íme a mesterségesintelligencia-verseny lehetséges nyertesei
2023. június 06. 13:04
A ChatGPT megjelenése után nagyon sokan fogtak bele saját nyelvi modelljük fejlesztésébe – több-kevesebb sikerrel. Vajon megelőzheti valamelyik az OpenAI-t? A Makronómon megvitatjuk, hogy milyen akadályokba üzközhettek a lemaradottak.
Az utóbbi időben nagyon népszerűek letttek a különböző chatbotok. A ChatGPT tavaly novemberi berobbanása után több vállalat és ország követte az OpenAI példáját, és fogott bele saját projektjébe.
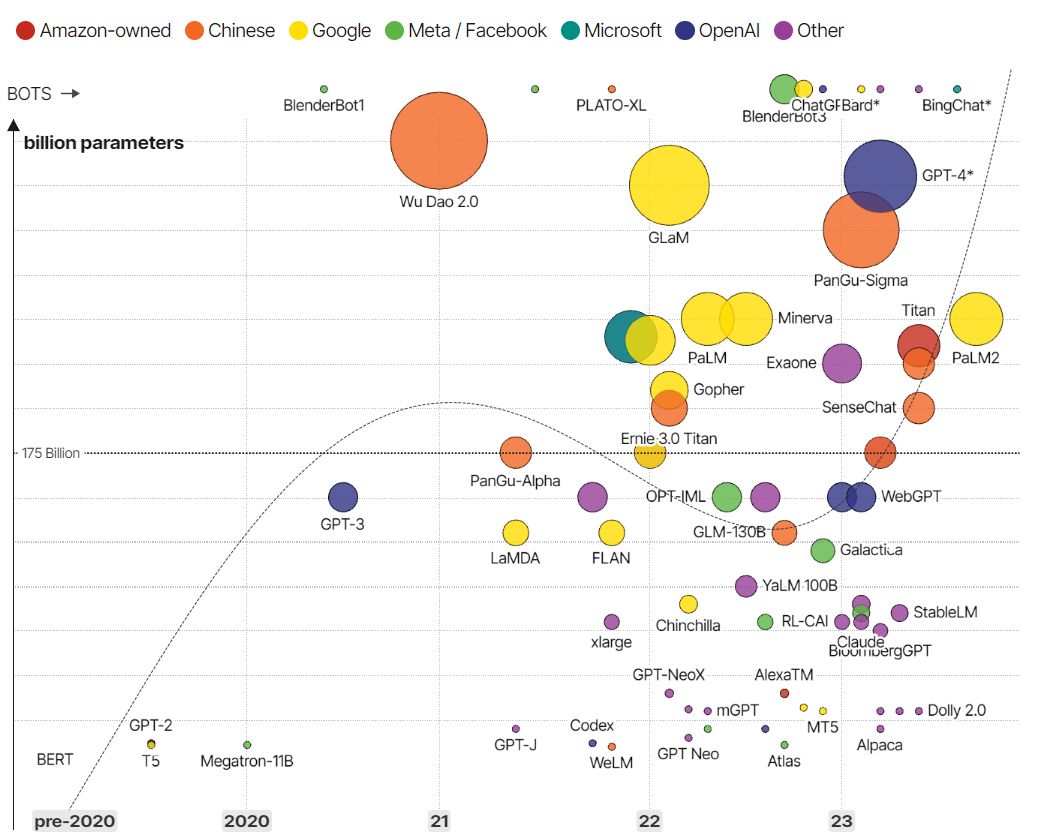
Ezekről a nagy nyelvi modellekről érdemes tudni, hogy hatalmas, emberi ésszel szinte felfoghatatlan mennyiségű adatból dolgoznak. Az alábbi ábra megmutatja, hogy a legnépszerűbb nyelvi modellek alkotói melyik évben dobták piacra a terméküket és hogy azok mennyi adatból gazdálkodnak.
Érdemes megfigyelni, hogy a sárga és narancssárga gömbökből van talán a legtöbb az ábrán, tehát mennyiségben a Google és Kína vezeti a mezőnyt. Azonban nem feltétlenül a mennyiség dönti el, hogy melyik vállalat vagy ország igazán eredményes. Tekintsük át, hogy hol hibázhatott e kettő a mesterségesintelligencia-versenyben.
A Google elkésett, Kína alapvetően hátránnyal indult
A fenti ábrán az is megfigyelhető, hogy a Google igencsak elkésett az OpenAI-hoz képest, és ezért valójában maga a vállalat felelős. Ahogyan a Makronóm már korábban beszámolt róla, 2018 körül Daniel de Freitas, a Google korábbi kutatómérnöke egy mesterségesintelligencia-mellékprojekten kezdett dolgozni. A célja az volt, hogy egy olyan csevegőbotot hozzon létre, amely az emberhez hasonlóan kommunikál.
Végül De Freitas és Shazeer létrehozta a Meenát, a chatbotot, amely képes volt filozófiáról vitatkozni, tévéműsorokról beszélgetni, sőt viccelődött is. Úgy vélték, hogy Meena gyökeresen megváltoztathatja az emberek online keresési módját – mondták el a Journalnak az egykori kollégák.
A chatbot fejlesztése közben azonban zsákutcába jutottak a mérnökök, miután a Google vezetői szerint az nem tartotta be a mesterséges intelligenciára vonatkozó biztonsági előírásokat. A vezetők többször is elutasították a két mérnök kérését, miszerint teszteljék azokat, majd a csevegőfunkciót adják hozzá a Google-asszisztenshez.
Ez tehát azt jelenti, hogy a Google a saját fejlődésének útjában állt, most pedig kapkod, hiszen a Microsoft megelőzte.
Kína esetén teljesen más akadályokról beszélhetünk. A ChatGPT-hez hasonló technológiák fejlesztéséhez elengedhetetlen, hogy legyen elég felhasználható adat, amiből „táplálkozik” – ez azonban a cenzúrázott online környezetben egyre nehezebben elérhető.
Hao Pej-csiang (Hao Peiqiang) volt vállalkozó és programozó szerint „az internetes iparban két problémával szembesülhetünk, amikor terméket készítünk: vagy nincs elég adatunk, vagy rengeteg cenzúrán kell átesniük. A nagy cégek megengedhetik maguknak, a kisebbek azonban nem.”
Tehát valójában, bár az ábrán látható, hogy a kínai Wu Dao 2.0 az akkori időkhöz képest – de még a mostanihoz viszonyítva is – elképesztően sok adatból gazdálkodott, mégsem tudott elterjedni olyan mértékben, mint például a ChatGPT.
Erre Sebestyén Géza, az MCC Gazdaságpolitikai Műhely vezetője is felhívja a figyelmet egy Facebook-posztban.
Hogyan lett a ChatGPT a legnépszerűbb nagy nyelvi modell?
A ChatGPT 3.5-ös verziója tavaly november végén jelent meg, és már akkor – bár kissé akadozva a leterheltség miatt – elérhető volt ingyenesen, bárki számára, akárcsak a legtöbb weboldal, így kifejezetten egyszerű volt hozzájutni és kipróbálni.
A kipróbálást követően pedig nem kellett sok idő ahhoz, hogy lássuk, mennyi mindenre használható ez a nagy nyelvi modell. Recepteket kérdezhettünk tőle, kódoltathattuk, sőt, az önéletrajzunkat is képes volt megírni. Ekkor persze felmerülhet a kérdés: ha ez ilyen egyszerűen elérhető és ennyi mindenre jó, miért is váltanánk?
Ekkor, nem sokkal a ChatGPT megjelenése után, a Google is beváltotta igéreteit és megalkotta saját chatbotját, a Bardot, amely nem igazán váltotta be a hozzá fűzött reményeket, ezáltal visszaterelte a felhasználókat az OpenAI termékéhez. A fejlesztések emellett folyamatosak a mai napig, azóta megjelent a ChatGPT 4, beépítették azt a Bingbe, sőt, mindez pluginokkal is kiegészült.
Összességében tehát a ChatGPT sikere az egyszerűségben és a minőségben rejlik, amelyet a mennyiség elé helyez.
Az alapvetően férfiak által dominált sport a nőket is rabul ejtheti: Kis-Szölgyémi Luca most, húszévesen a legjobb női kormányos lett. Személyes beszámoló következik tőle.
Sovány vigasz, hogy az Európai Unió tagállamai közül Portugália nem sokkal előz meg minket, Horvátország, Görögország és Bulgária pedig még nálunk is borúlátóbb.
A miniszterelnök a stábja társaságában jelentkezett be.
p
5
2
3
Hírlevél-feliratkozás
Ne maradjon le a Mandiner cikkeiről, iratkozzon fel hírlevelünkre! Adja meg a nevét és az e-mail-címét, és elküldjük Önnek a nap legfontosabb híreit.
Összesen 8 komment
A kommentek nem szerkesztett tartalmak, tartalmuk a szerzőjük álláspontját tükrözi. Mielőtt hozzászólna, kérjük, olvassa el a kommentszabályzatot.
Sorrend:
pandalala
2023. június 06. 17:54
Kérdezd meg Grétát vagy az AI-t. Ők biztos tudják! :-))
Válasz erre
1
0
h040183
2023. június 06. 14:54
"a ChatGPT sikere az egyszerűségben és a minőségben rejlik, amelyet a mennyiség elé helyez"
Érdekes, hogy a Google is így kezdte, aztán sok c-szintű vezető kiépítette a saját kiskirályságát, és mostmár minden komplikált lett, ami Google.
Válasz erre
2
0
síróbohóc
2023. június 06. 14:27
Ez vajon a technikai evolúció által az árok szélén hagyott, jövőkép nélküli, frusztrált, vidéki mandinerolvasóknak a horror vagy a scifi kategórába eső hír?
Válasz erre
0
1
snowwolf
2023. június 06. 12:09
Arra vagyok csak kíváncsi, hogy a Big Data-nak, amelyből a MI "táplálkozik", mekkora az ökolábnyoma. Azért kérdezem csak, mert Hollandiában is és Írországban is zárják be a tehénfarmokat az CO2 kibocsátásra hivatkozva. Szerintem a Big Data szervereinek a működtetése, hűtése nem kispályás fogyasztást eredményez, mégsincs valahogy szó róla a mainstream-ben.
Válasz erre
1
1
Jelenleg csak a hozzászólások egy kis részét látja. Hozzászóláshoz és a további kommentek megtekintéséhez lépjen be, vagy regisztráljon!