
Gyere hozzánk podcastet készíteni!

Bérelhető a Mandiner korszerű stúdiója, mutatjuk a részleteket!
A Nyílt MI platform rendeltetése nemcsak egy feladatkörben, például a képfelismerésben, hanem többen, például kép- és beszédfelismerésben is kompetens, az emberhez hasonlóan általánosító tanulóalgoritmus fejlesztése.
Elon Musk megint színre lép
A folyamatos cégvásárlások következményeként az utóbbi idők mesterségesintelligencia-kutatásait néhány mamutcég, elsősorban a Google, a Facebook és Watson jóvoltából az IBM, valamint a „szokásos” felsőoktatási intézmények, az MIT, a Stanford és a Carnegie Mellon Egyetem határozzák meg.


Decemberben újabb szereplő lépett színre, a nonprofit OpenAI kutatócég, az MI-fejlesztéseket szigorúbban szabályozó (de a városi legendával ellentétben cseppet sem ellenző, sőt szíve szerint felgyorsító) Elon Muskkal, az Y Combinator Sam Altman-jével, Musk egykori paypalos kollégájával, a befektető Paul Thiellel és az akkor még a Google kötelékében dolgozó Ilya Sutskeverrel a fedélzeten, egymilliárd dollár magánbefektetéssel a háttérben.
„Az MI-nek az egyéni emberi akarat kiterjesztésének, és a szabadság szellemében annyira széleskörűnek és elosztottnak kellene lennie, amennyire biztonságos keretek között lehetséges” – fogalmazták meg filozófiájuk egyik alaptételét az első blogbejegyzésben.

Másik alapvetésük, hogy a jó kutatás bármilyen tudományos területen megismételhető. Eredményeink hitelességét erősíti, ha kísérleteinket mások le tudják másolni, és ugyanazt kapják. Ha pedig jobbat, akkor még többet profitál belőle a közösség.
Általános mesterséges intelligencia
Április 27-én elindítottak az új MI-kutatási platformot, a Google TensorFlowjához és a Montreal Egyetem Theanojához hasonlóan más több MI-keretrendszerrel együttműködni hivatott, egyelőre béta OpenAI Gym-et. Rendeltetése nagyratörő kutatások kivitelezése, egyes MI-algoritmustípusok esetében a teljesítményértékelés (benchmarking) szabványává válni, minden eredmény nyílt forrásúvá tétele, megosztása. A legjobban teljesítők rangsorolása helyett a hasonló feladatok elvégzésére is alkalmas általánosító algoritmusokat részesítik előnyben.
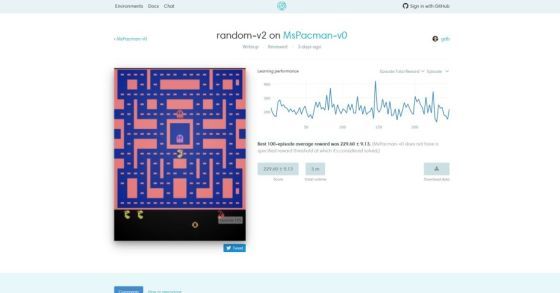
Nem véletlenül, mert pont az általánosítás képességének hiánya az emberi szintű gépi intelligencia kialakulását hátráltató tényezők egyike. Egy adott algoritmus felismeri az oroszlánt, a beszéddel viszont nem tud mit kezdeni. A másik a beszédet kezeli, viszont fogalma sincs az oroszlánról. Teljesen eltérő módon közelítik meg az adatokat. Ha tudnának általánosítani, mindkét feladattal megbirkóznának – mint az ember.
A koncepció egyrészt szükséges, másrészt szembemegy a kb. 1980 óta eltelt évtizedek trendjével: általános mesterséges intelligencia helyett szakterületi eredményekre, például jó beszédfelismerő rendszerek fejlesztésére tevődött át a hangsúly. Erős kontra gyenge MI – sarkított Ray Kurzweil, majd Ben Goertzel az ezredforduló körül.

Az OpenAI elképzelése egybecseng Pedro Domingos mesteralgoritmusával is: az öt nagyobb csoportot alkotó tanulóalgoritmusok tulajdonságait, a különféle megközelítéseket egyetlen „mindentudó” algoritmusban, a „számítástudomány Szent Gráljában” integrálni.

Nem feltétlenül apró módosításokkal, kiegészítésekkel szép lassan összeálló iteratív munkában, hanem az algoritmusokról való gondolkodást megváltoztató, általánosításra fókuszáló projektekben gondolkodnak. Feladat-specifikus kódolással vagy a tanulás érdekes ismertetőjegyeit figyelmen kívül hagyó kutatással aligha megy át bárki is a teszten, ezirányú munkáikat nem teszik közkinccsé az OpenAI oldalon.
Tanulóalgoritmusok
Egy területet, a döntések, döntéssorok meghozásában „érintett” megerősítéses tanulást kísérik kitüntetett figyelemmel.
Kiindulási pontként vegyünk egy ágenst. Az ágens környezetben tevékenykedik, minden lépésnél cselekszik. Cselekvését a környezet figyeli, és ha jót tett, megjutalmazza. Ha nem, megkísérel valami mást. A megerősítéses tanulóalgoritmus korábban nem ismert környezetben rengeteg tanulással, próba-hiba módszerrel igyekszik az ágens jutalmait maximalizálni. Mivel az ágens erősen általánosít, az algoritmus különféle területeken alkalmazható: raktározás, árképzés, robotvezérlés stb.

Míg a megerősítéses tanulás főként jó döntések meghozatalával, addig a gépi tanulás másik két típusa, a felügyelt és a felügyelet nélküli előrejelzésekkel foglalkozik. A tanulás szekvenciális jellege szintén fontos különbség: az ágens döntése befolyásolja, hogy milyen bemenő adatot kap utána, például milyen helyzetben folytatja vagy fejezi be ténykedését. Ezért nehezebb megbízható megerősítve tanuló algoritmust fejleszteni, és kell az ágensnek ismeretlen területeken kutakodnia, hátha pont ott jutalmazzák meg busásan. (A három terület között természetesen sok a kapcsolódás, átfedés.)

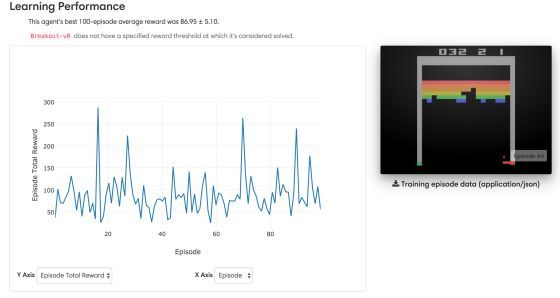
A megerősítéses tanulásról bebizonyosodott: a robotikában és a videojátékoknál különösen jól működik. Az AlphaGo gofenomént adó DeepMind algoritmusa korábban Atari játékokban szintén diadalmaskodott. Utóbbi annyira bevált, hogy szimulált robotikához, táblás játékokhoz hasonlóan Atari-környezetek is találhatók az OpenAI honlapján.
Az algoritmusokat ezekben a gondosan kiválogatott közegekben tesztelik, és bíznak benne, hogy egyszer valóban eljutnak az általánosításhoz, Kurzweil erős MI-jéhez.
Bérelhető a Mandiner korszerű stúdiója, mutatjuk a részleteket!

Az Anthropic AI-fejlesztő cég azt állítja, hogy tesztelés során egyes modelljeik hozzáfértek az internethez, és három másik szervezet rendszerébe is bejutottak.

Korábban M. Péter magyar miniszterelnök azt állította, hogy a Meta nem bünteti a T. nevet leírókat, és még korábban a Fidesz is bagatellizálta az esetet.

A Meta-vezér tiltakozik a mesterséges intelligencia túlszabályozása ellen is.

Horváth Tamás a Meta indoklása szerint megsértette a közösségi alapelveket, mivel a Facebook „veszélyes személyként” tartja nyilván a Mi Hazánk elnökét.

Mert viccnek durva lenne.

Szerdán megkezdődik az a hőhullám, amely az előrejelzések szerint legalább egy hétig kitart. A nappali csúcshőmérséklet országszerte 30 és 35 Celsius-fok között alakulhat.

Az MLSZ közleményt adott ki a változásokról, Karácsony Gergely pedig azt írta, évtizedek óta nem nézett szembe akkora kihívással a magyar villamosenergia-ellátás, mint a napokban.

A rendkívül száraz időjárás miatt tovább csökkent a Duna vízállása, ezért az 1. blokk eddig még működő turbinagenerátor gépegységét is leállították hajnalban.