
Gyere hozzánk podcastet készíteni!

Bérelhető a Mandiner korszerű stúdiója, mutatjuk a részleteket!
Az IBM Watsonja nem pihen, most nyelvi képességeit pallérozza: hírügynökségi jelentésekből generál összefoglalókat.
A 2011-ben Jeopardy bajnokokat legyőző Watson az utóbbi évek és a jelen egyik legizgalmasabb, legígéretesebb mesterségesintelligencia-fejlesztése.
A kutatók most dokumentumok lényegét naprakész módszerekkel kiemelő rendszert alkotnak a híres IBM-platformból. Mélytanulás-módszerekkel próbálják pallérozni Watson kérdéseket megválaszoló algoritmusát. Az algoritmus többmillió angol nyelvű hírügynökségi jelentés alapján készített rövid összefoglalókat.


„A szöveg összefoglalására fókuszálunk, ami bemenet-kimenet viszonylatban lényegében szavakból álló célszakasz kialakítása a forrásdokumentum szavainak bemenő szakaszából. Ezt a célszakaszt hívják összefoglalónak ” – írják a kutatók.
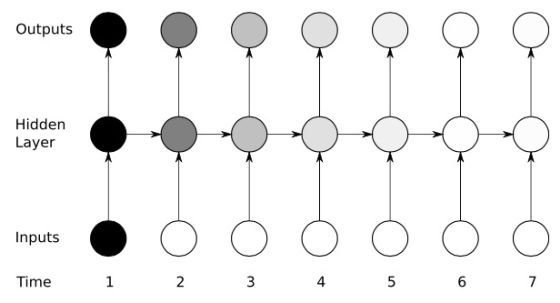
A mélytanulás-alapú „szakasztól szakaszig” megközelítést a gépi fordításban használják leggyakrabban.
Egy szöveg kivonatolása jelentősen különbözik az összefoglalótól. Az összefoglaló általában rövid, hosszúsága nem függ a dokumentum hosszától, és elfogadott, hogy az alapgondolat kivételével mindent kihagyunk belőle.
A kutatók hangsúlyozzák, hogy ideghálójuk jobb teljesítményt nyújt, mint a Facebook által ugyanerre a célra használt friss csúcsmodell.
„Az általuk készített szövegek meglepően jók, a legtöbbről simán elhihető, hogy ember írta” – állítják a kutatók.
Összefoglalók készítése mindenképpen fontos, ha valóban az a cél, hogy a számítógépek ugyanolyan jól értsék a nyelvet, mint mi magunk.
Bérelhető a Mandiner korszerű stúdiója, mutatjuk a részleteket!

Az Anthropic AI-fejlesztő cég azt állítja, hogy tesztelés során egyes modelljeik hozzáfértek az internethez, és három másik szervezet rendszerébe is bejutottak.

Korábban M. Péter magyar miniszterelnök azt állította, hogy a Meta nem bünteti a T. nevet leírókat, és még korábban a Fidesz is bagatellizálta az esetet.

Horváth Tamás a Meta indoklása szerint megsértette a közösségi alapelveket, mivel a Facebook „veszélyes személyként” tartja nyilván a Mi Hazánk elnökét.

Kedden találkozott egymással az elemző és a köztársasági elnöki pozíciót is betöltő Forsthoffer Ágnes.

Éjszakára lekapcsolnák számukra a közösségi felületeket.

Gyurcsány volt embere kilép a pártból is.

Az MLSZ közleményt adott ki a változásokról, Karácsony Gergely pedig azt írta, évtizedek óta nem nézett szembe akkora kihívással a magyar villamosenergia-ellátás, mint a napokban.

A rendkívül száraz időjárás miatt tovább csökkent a Duna vízállása, ezért az 1. blokk eddig még működő turbinagenerátor gépegységét is leállították hajnalban.