
Gyere hozzánk podcastet készíteni!

Bérelhető a Mandiner korszerű stúdiója, mutatjuk a részleteket!
Masszív képi adatbázis alapján tanulják meg algoritmusok, hogy egy jelenetben többet lássanak egy-egy tárgy színénél és formájánál. Értelmezniük kell a képet.
A Stanford Egyetem Mesterséges Intelligencia Laboratóriumában fejlesztett Vizuális Genom nevű képadatbázis rendeltetése, hogy számítógépek rajta keresztül tanuljanak meg képeket értelmezni, jöjjenek rá, mi történik a képen. Ha a képeket valamelyest megértik, akkor a való világból, a valóságból is többet felfognak.
A Vizuális Genom képeit gazdagabban felcímkézték, mint a labort vezető Fei-Fei Li által korábban fejlesztett ImageNet adatbázist. Az ImageNet 1 milliónál több, tartalmuk szerint felcímkézett kép gyűjteménye.

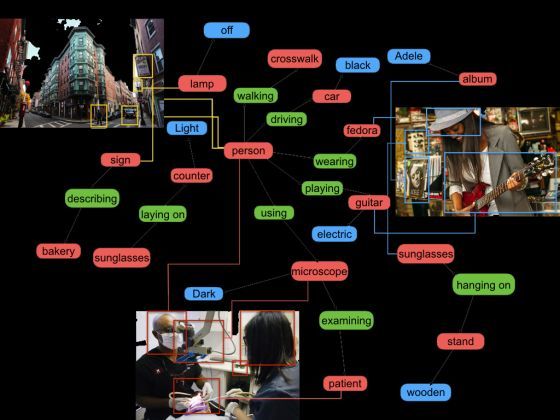
Li szerint a mesterségesintelligencia-kutatás szempontjából kulcsfontosságú, hogy a számítógépeknek megtanítsanak képeket elemezni és értelmezni. A Vizuális Genom képein, jelenetein tanuló algoritmusok elvileg lehetővé teszik, hogy például robotok vagy önvezető autók pontosan lássák a környező világot, és értelmet adjanak annak, amit látnak.
Ezekkel az algoritmusokkal a hatékonyabb kommunikáció és az is megtanítható számítógépeknek, hogy egyáltalán hogyan kommunikáljanak.
„A gépi látás legnehezebben megoldható kérdéseire összpontosítunk, hogy mi is köti össze valójában az érzékelést a gondolkodással. Nem csak pixeladatokról, színük, árnyalataik, formájuk és hasonlók értelmezéséről, hanem a háromdimenziós és szemantikus képi világ teljesebb megértéséről van szó” – magyarázza Li.
Bérelhető a Mandiner korszerű stúdiója, mutatjuk a részleteket!

Éjszakára lekapcsolnák számukra a közösségi felületeket.

Ezt támasztja alá a Samsung negyedéves jelentése is: a vállalat üzemi eredménye a memóriachipek iránti növekvő keresletnek köszönhetően rekordmértékben emelkedett.

Sajnálom, ha ezzel valakinek a kicsi lábfejére lépek, de ez így nem fog menni.

Már veszik vissza az embereket, nem jött össze a költségcsökkentés.

Peter Thiel, a libertárius nézeteiről ismert kaliforniai tech guru nem kér a mesterséges intelligencia szabályozásából.

Az amerikai kormányzat előbb ellenőrizni akarja az egyre fejlettebb AI-modelleket, mielőtt megengednék a nagyvilág felé való terjesztésüket.

Nagy Gábor Bálint nem kíván tovább részese lenni annak, hogy a személye körül gerjesztett, valótlan alapokon álló, politikai célt szolgáló konfliktus az intézményi bizalom további erodálásának eszközévé váljon.

A saját hangomra sem ismerek rá ilyenkor. Ki ez, aki itt most megszólalt? Jó kérdés, eddig nem találtam megnyugtató választ rá. Győrffy Ákos írása.